I want everything local — no cloud, no remote code execution.
That’s what a friend said. That one-line requirement, albeit simple, would need multiple things to work in tandem to make it happen.
What does a mainstream LLM (Large Language Model) chat app like ChatGPT or Claude provide at a high level?
- Ability to use chat with a cloud hosted LLM,
- Ability to run code generated by them mostly on their cloud infra, sometimes locally via shell,
- Ability to access the internet for new content or services.
With so many LLMs being open source / open weights, shouldn't it be possible to do all that locally? But just local LLM is not enough, we need a truely isolated environment to run code as well.
So, LLM for chat, Docker to containerize code execution, and finally a browser access of some sort for content.
🧠 The Idea
We wanted a system where:
- LLMs run completely locally
- Code executes inside a lightweight VM, not on the host machine
- Bonus: headless browser for automation and internet access
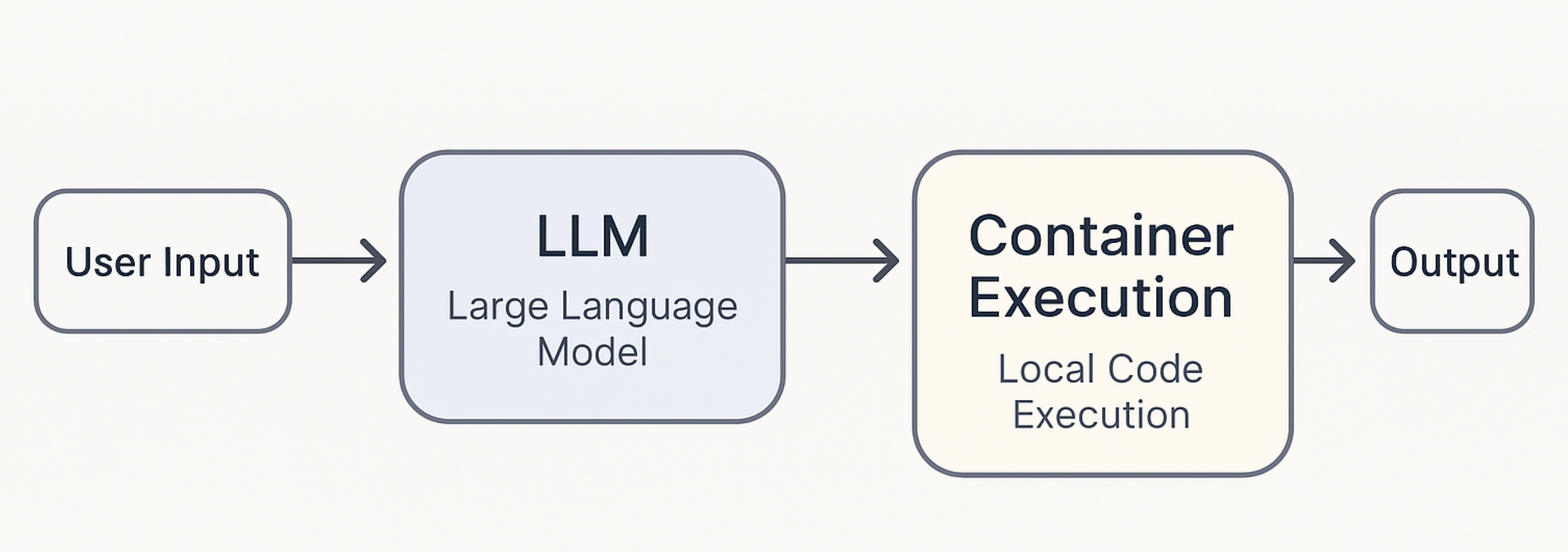
The idea was to perform tasks which require privacy to be executed completely locally, starting from planning via LLM to code execution inside a container. For instance, if you wanted to edit your photos or videos, how could you do it without giving your data to OpenAI/Google/Anthropic? Though they take security seriously (more than many), it's just a matter of one slip leading to your private data being compromised, a case in point being the early days of ChatGPT when user chats were accessible from another's account!
The Stack We Used
- LLMs: Ollama for local models (also private models for now)
- Frontend UI: `assistant-ui`
- Sandboxed VM Runtime: `container` by Apple
- Orchestration: `coderunner`
- Browser Automation: Playwright
💡 We ran this entirely on Apple Silicon, using
containerfor isolation.
🛠️ Our Attempt at a Mac App
We started with zealous ambition: make it feel native. We tried using a0.dev, hoping it could help generate a Mac app. But it appears to be meant more for iOS app development — and getting it to work for MacOS was painful, to say the least.
Even with help from the "world's best" LLMs, things didn't go quite as smoothly as we had expected. They hallucinated steps, missed platform-specific quirks, and often left us worse off.
Then we tried wrapping a NextJS app inside Electron. It took us longer than we'd like to admit. As of this writing, it looks like there's just no (clean) way to do it.
So, we gave up on the Mac app. The local web version of assistant-ui was good enough — simple, configurable, and didn't fight back.
Assistant UI
We thought Assistant-UI provided multiple LLM support out-of-the-box, as their landing page shows a drop-down of models. But, no.
So, we had to look for examples on how to go about it, and ai-sdk appeared to be the popular choice.
Finally we had a dropdown for model selection. We decided not to restrict the set to just local models, as smaller local models are not quite there just yet. Users can get familiar with the tool and its capabilities, and later as small local models become better, they can just switch to being completely local.
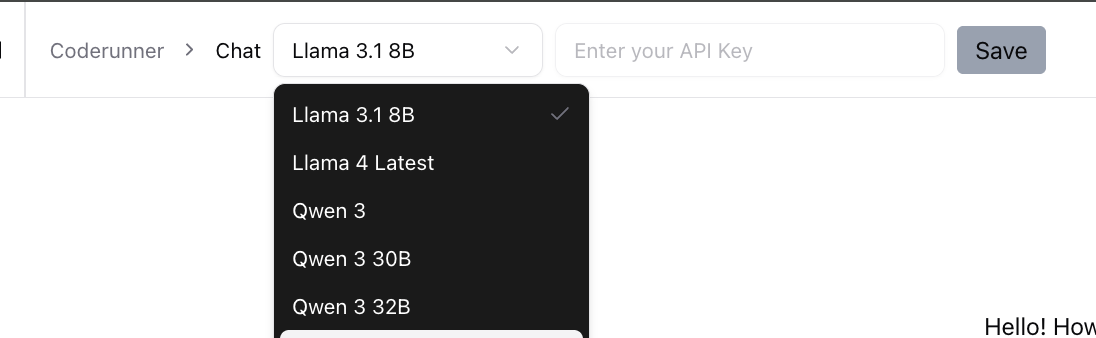
Tool-calling
Our use-case also required us to have models that support tool-calling. While some models do, Ollama has not implemented the tool support for them. For instance:
responseBody: '{"error":"registry.ollama.ai/library/deepseek-r1:8b does not support tools"}',And to add to the confusion, Ollama has decided to put this model under tool calling category on their site. Understandably, with the fast-moving AI landscape, it can be difficult for community driven projects to keep up.
At the moment, essential information like whether a model has tool-support or not, pricing per token, for various models are so fickle. A model's official page mentions tool-support but then tools like Ollama take a while to implement them. Anyway, we shouldn't complain - it's open source, we could've contributed.
Containerized execution
After the UI was MVP-level sorted, we moved on to the isolated VM part. Recently Apple released a tool called 'Container'. Yes, that's right. So, we checked it out and it seemed better than Docker as it provided one isolated VM per container - a perfect fit for running AI generated code.
So, we deployed a Jupyter server in the VM, exposed it as MCP (Model Context Protocol) tool, and made it available at http://coderunner.local:8222/mcp.
The advantage of MCPing vs a exposing an API is that existing tools that work with MCPs can use this right away. For instance, Claude Desktop and Gemini CLI can start executing AI-generated code with a simple config.
"mcpServers": {
"coderunner": {
"httpUrl": "http://coderunner.local:8222/mcp"
}
}As you can see below, Claude figured out it should use the tool execute_python_code exposed from our isolated VM via the MCP endpoint.
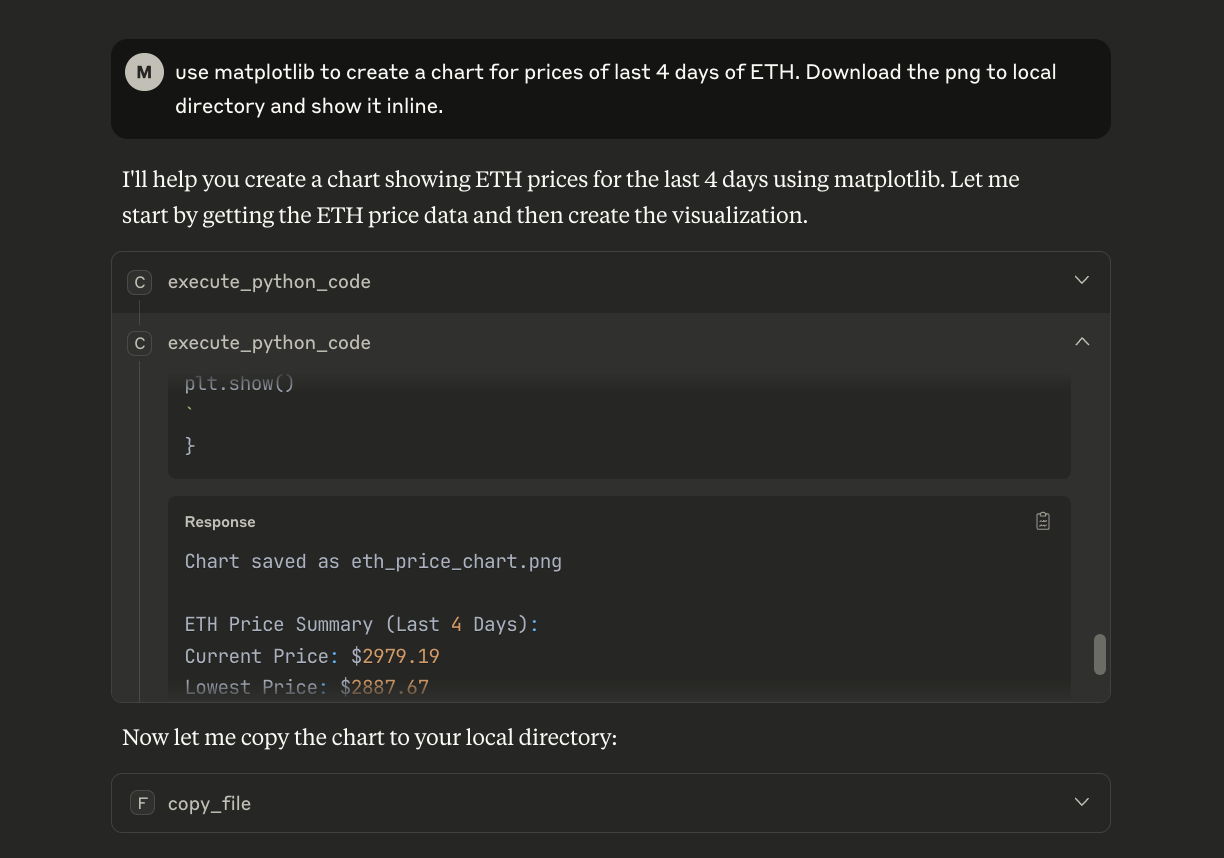 Aside - if you want to just use the
Aside - if you want to just use the coderunner bit as an MCP to execute code with your existing tools, the code for coderunner is public.
Apple container
A tangent - if you're planning to work with Apple
containerand building VM images using it, have an abundance of patience. The build keeps failing withTraperror or just hangs without any output. To continue, you shouldpkillall container processes and restart thecontainertool. Then remove thebuildkitimage so that the nextbuildprocess fetches a fresh one. And repeat the three steps till it successfully works; this can take hours. We are excited to see Apple container mature as it moves beyond its early stages.
Back to our app, we tested the UI + LLMs + CodeRunner on a task to edit a video and it worked!
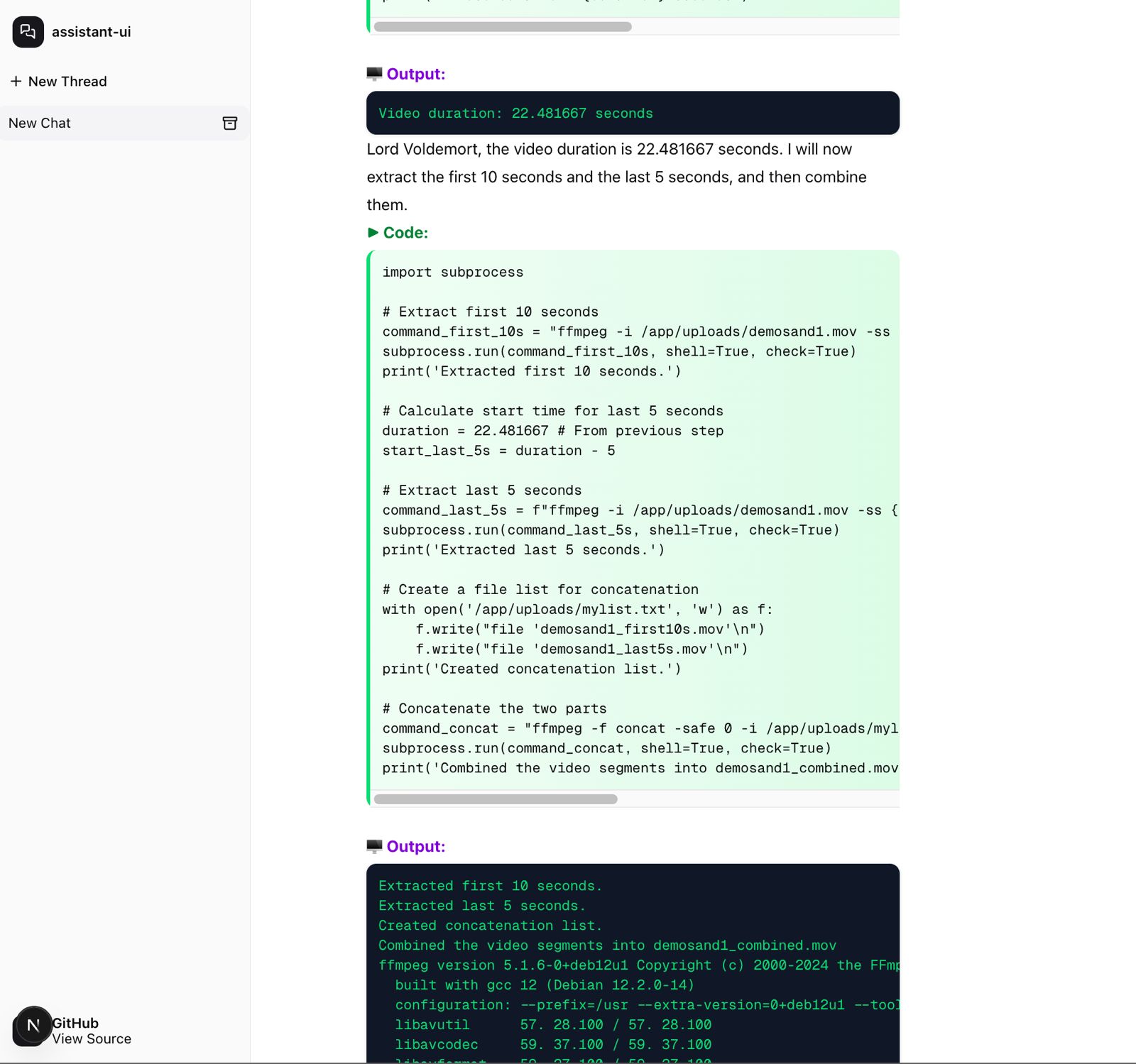 I asked it to address me as Lord Voldemort as a sanity check for system instructions
I asked it to address me as Lord Voldemort as a sanity check for system instructions
After the coderunner was verified to be working, we decided to add the support of a headless browser. The main reason was to allow the app to look for new/updated tools/information online, for example, browsing github to find installation instruction for some tool it doesn't yet know about. Another reason was laying the foundation for research.
We chose Playwright for the task. We deployed it in the same container and exposed it as an MCP tool. Here is one task we asked it to do -
With this our basic set up was ready: Local LLM + Sandboxed arbitrary code execution + Headless browser for latest information.
What It Can Do (Examples)
- Do research on a topic
- Generate and render charts from CSV using plain English
- Edit videos (via
ffmpeg) — e.g., “cut between 0:10 and 1:00” - Edit images — resize, crop, convert formats
- Install tools from GitHub in a containerized space
- Use a headless browser to fetch pages and summarize content etc.
Volumes and Isolation
We mapped a volume from
~/.coderunner/assets (host)
to
/app/uploads (container)
So files edited/generated stay in a safe shared space, but code never touches the host system.
Limitations & Next Steps
- Currently only works on Apple Silicon (macOS 26 is optional)
- Needs better UI for managing tools and output streaming
- Headless browser is classified as bot by various sites
Final Thoughts
This is more than a just an experiment. It's a philosophy shift bringing compute and agency back to your machine. No cloud dependency. No privacy tradeoffs. While the best models will probably be always with the giants, we hope that we will still have local tools which can get our day-to-day work done with the privacy we deserve.
We didn't just imagine it. We built it. And now, you can use it too.
Check out
coderunner-uion Github to get started, and let us know what you think. We welcome feedback, issues and contributions.