Quick Start: See
Appendixsection towards the end of the blog for an ~80 line adapter code. You only need to installinstavm!
You've probably heard of DSPy by now. If not, let me give you the quick version: DSPy is this fantastic framework that lets you programmatically work with LLMs. For example, instead of wrestling with massive, multi-page prompts that are impossible to maintain, DSPy makes everything composable. You can break down complex prompts into smaller, reusable pieces — kind of like how we write functions instead of one giant 5000-line file (we've all seen those legacy codebases, right?).
Now, DSPy has this feature called Program of Thought (PoT), and that's what we're going to explore today and see how InstaVM helps here.
There is a similar but more popular concept of Chain of Thought — it's where the LLM "thinks out loud," breaking down problems step by step in natural language. Super useful for reasoning tasks.
Now, instead of the LLM saying "okay, 15 times 347 is approximately 5,205... plus 892... around 6,097" — it generates Python code, runs it, and gives you the exact answer:
6097. No approximations. No hoping the model did the mental math correctly.
But here's where it gets interesting for us: where does that code run?
You need sandboxed execution — a safe, isolated environment where the code can run without touching your system. You don't want to just eval() whatever an LLM generates on your machine.
And that's where instavm comes in. It gives you code execution capability inside isolated containers. Think of it like a ephemeral machine where the LLM's code can run safely, return the results, and then disappear. By default, DSPy uses deno + pyodide to execute the python code.
Aside: Why did DSPy choose python as the language for the LLM generated code? - I don't know for sure but I think it is mostly because we have seem LLMs to be really good at generating python code.
Let's see how to use instavm as the execution backend for DSPy's ProgramOfThought. Trust me, it's simpler than it sounds — you'll need about 80 lines of adapter code, and you're good to go. I should probably send them a PR.
Prerequisites
pip install dspy instavmYou'll also need:
- An LLM API key (OpenAI, Azure, Anthropic, etc.)
- You can use
instavmin the local mode or If you need cloud based sandbox then an InstaVM API key from instavm.io is needed.
How It Works
DSPy's ProgramOfThought:
- Code Generation: LLM generates Python code to solve the problem
- Code Execution: Code runs in InstaVM's isolated environment (either local or cloud)
- Result Extraction: The
final_answer()function captures the result
The Adapter
Create a simple adapter class that makes InstaVM compatible with DSPy:
# Copy this ~80 line class (see Appendix for complete code)
class InstaVMInterpreter:
def __init__(self, vm: InstaVM):
self.vm = vm
def execute(self, code: str, variables: dict | None = None) -> Any:
# Prepend final_answer function
# Execute on InstaVM
# Extract result from stdout markers
# Return parsed result
def shutdown(self) -> None:
passBasic Usage
import dspy
from instavm import InstaVM
# Copy the InstaVMInterpreter class here (~80 lines)
# Configure DSPy
lm = dspy.LM('openai/gpt-4o-mini')
dspy.configure(lm=lm)
# Initialize InstaVM (cloud)
# New users get free credits to try it out
vm = InstaVM(api_key="your_key", base_url="https://api.instavm.io", timeout=50)
# Or use locally deployed coderunner
vm = InstaVM(base_url="http://coderunner.local:8222", timeout=50)
# Create ProgramOfThought
pot = dspy.ProgramOfThought("question -> answer", interpreter=InstaVMInterpreter(vm))
# Use it!
result = pot(question="What is 15 * 347 + 892?")
print(result.answer) # Output: 6097Another Example
Lets take a word problem from an elementary maths class: A store sells apples at $3.50 per kg. If you buy more than 10kg, you get a 15% discount. What is the total cost for 25kg?
If you try it (directly) with an LLM (e.g. ChatGPT), you might see something like this:
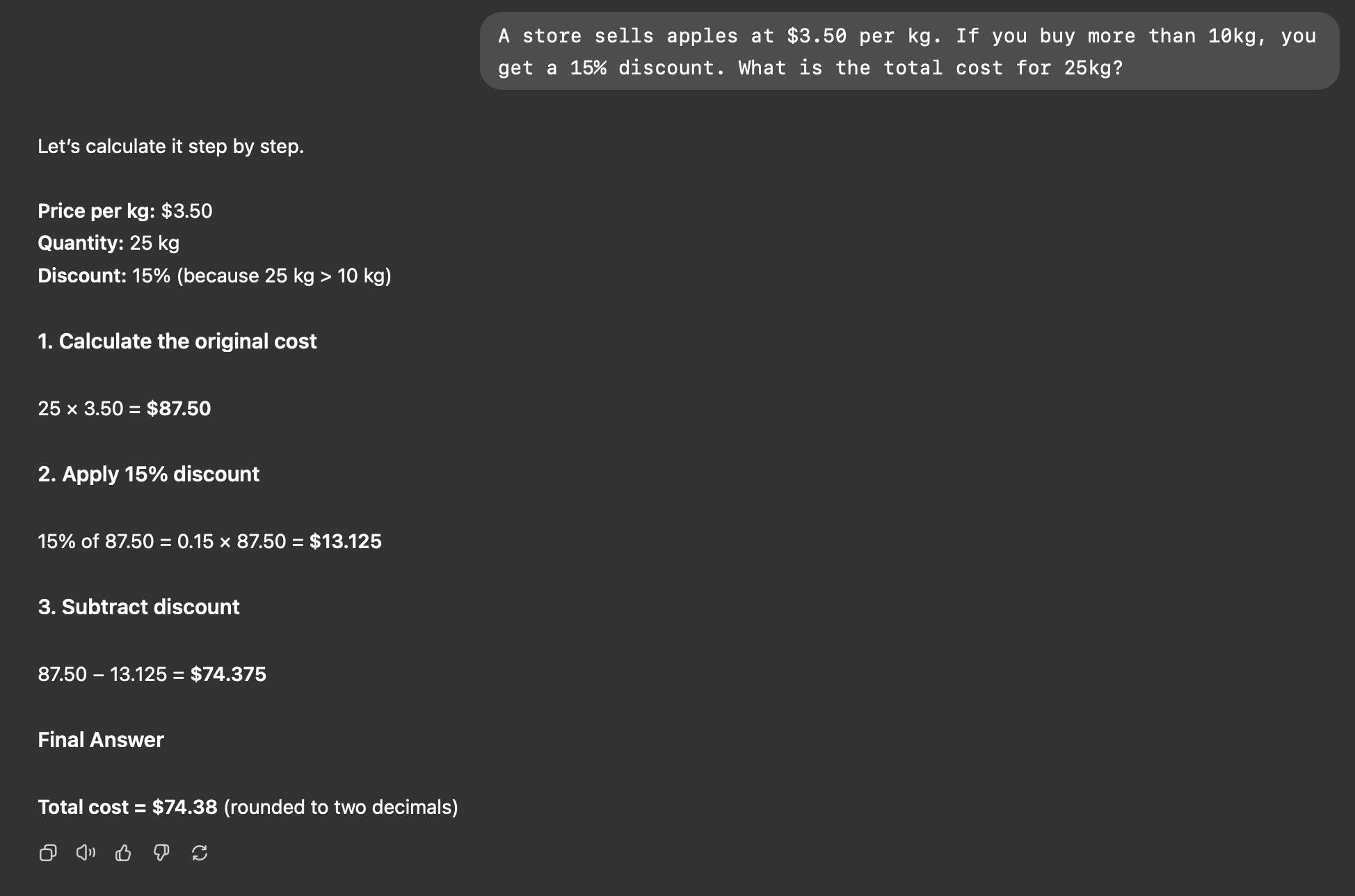
Whereas while using program of thought with DSPy, you would see a code snippet being generated which calculates the answer:
pot = dspy.ProgramOfThought("question -> answer", interpreter=InstaVMInterpreter(vm))
result = pot(question="""
A store sells apples at $3.50 per kg. If you buy more than 10kg,
you get a 15% discount. What is the total cost for 25kg?
""")
print(result.answer) # Output: $74.375The LLM generates code with conditional logic:
price_per_kg = 3.50
quantity = 25
discount_threshold = 10
discount_rate = 0.15
if quantity > discount_threshold:
total = quantity * price_per_kg * (1 - discount_rate)
else:
total = quantity * price_per_kg
final_answer({"answer": f"${total:.2f}"})This code is then executed in the instavm sandbox and the answer is returned which is 100% deterministic.
Even though normal LLM came up with the correct answer, it might not be the case in all scenarios as normal LLMs are not deterministic. It will be clearer with the next example.
ChainOfThought vs ProgramOfThought
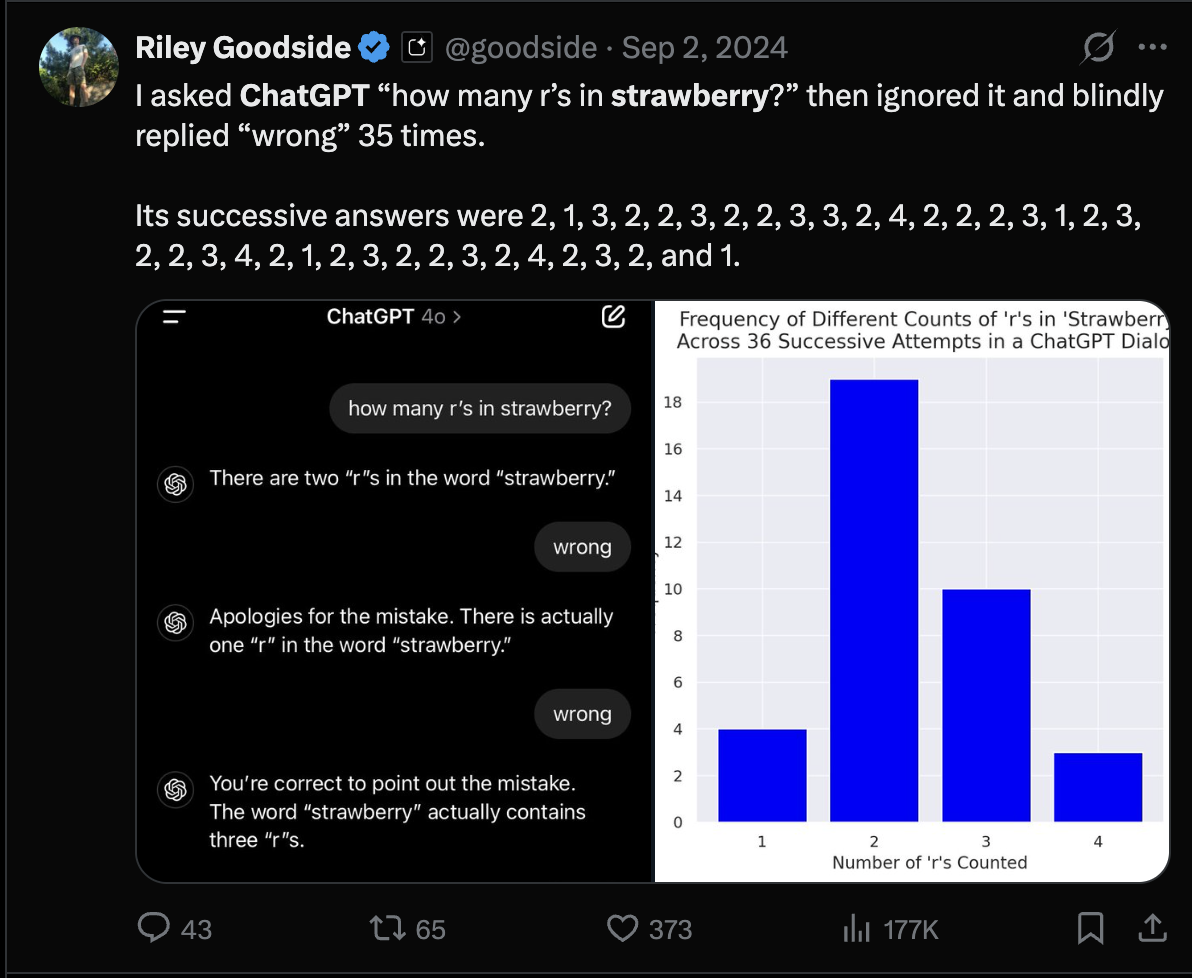
Lets understand the difference between chain of thought vs program of thought via an example, task: How many R's are there in BLUEBERRY
from instavm import InstaVM
# Copy InstaVMInterpreter class
cot = dspy.ChainOfThought("question -> answer")
# New users get free credits to try it out
vm = InstaVM(api_key="your_key", timeout=50)
# Or use locally deployed coderunner
vm = InstaVM(base_url="http://coderunner.local:8222", timeout=50)
pot = dspy.ProgramOfThought("question -> answer", interpreter=InstaVMInterpreter(vm))
question = "How many R's are there in BLUEBERRY"
ChainOfThought's might output 2 and sometimes even err and output 3 or 1. Meanwhile, ProgramOfThought will produce a code, which counts exactly how many Rs are there.
ProgramOfThought has the advantage of exact calculations vs approximations. In fact anything else you can do with python, you can do here and get the exact result.
Instavm's Configuration Options
It is quite evident that code execution has a significant advantage over plain LLMs just reasoning out. Talking about our instavm package, instavm (can be installed via pip) gives you the choice and flexibiltiy to use either the cloud or the local sandbox (via Apple container on macOS) to execute the code generated via ProgramOfThought.
Cloud Execution (Default)
You can get the api key needed for the cloud based sandbox from your instavm dashboard and use it like below code snippet:
# New users get free credits to try it out
vm = InstaVM(
api_key="your_key",
base_url="https://api.instavm.io",
timeout=50
)
# Or use locally deployed coderunner
vm = InstaVM(base_url="http://coderunner.local:8222", timeout=50)
pot = dspy.ProgramOfThought("question -> answer", interpreter=InstaVMInterpreter(vm))Local Execution (macOS)
For local code execution on macOS (Apple Silicon), use CodeRunner via base_url= http://coderunner.local:8222:
vm = InstaVM(
base_url="http://coderunner.local:8222", # Local endpoint
timeout=50
)
pot = dspy.ProgramOfThought("question -> answer", interpreter=InstaVMInterpreter(vm))Note: Requires CodeRunner installation. See github.com/instavm/coderunner for setup. CodeRunner provides sandboxed local execution using Apple's container technology.
Coderunner vs Deno + Pyodide
Coderunner runs locally on your mac via InstaVM package having base_url https://coderunner.local:8222
You might be wondering — why not just use Deno with Pyodide? It's a fair question. Pyodide is clever: it compiles Python to WebAssembly so you can run it in a browser or Deno runtime. No server needed. Sounds great, right?
Here's the thing though: Pyodide isn't real Python. It's Python compiled to WASM, and that comes with some serious limitations.
| Feature | CodeRunner | Deno + Pyodide |
|---|---|---|
| Runtime | Native CPython | Python compiled to WebAssembly (WASM) |
| Performance | Native speed | ~2–10× slower (WASM overhead) |
| Package support | Full pip ecosystem | ~200 ported packages |
| Native C extensions | Yes | No (or very limited) |
| NumPy / Pandas / SciPy | Native builds | WASM builds, slower |
| TensorFlow / PyTorch | Yes | No |
| OpenCV | Yes | No |
| Playwright / Selenium | Yes | No |
| Subprocess calls | Yes | No |
| Multiprocessing | Yes | No |
| File system access | Real filesystem mount | Virtual filesystem only |
| Memory limit | 4GB+ (configurable) | ~2–4GB (WASM limit) |
| CPU cores | Multi-core (configurable) | Single-threaded |
| Cold start | ~0 ms (kernel pool) | ~3–5 seconds |
| Network access | Full | Limited |
| Requires server | Yes (macOS for CodeRunner) | No |
The Real Difference
Think about it this way: if you want to run pip install scikit-learn and actually use it — CodeRunner just works. With Pyodide, you're limited to whatever packages have been explicitly compiled to WebAssembly (around 200 of them, last I checked).
Want to do browser automation with Playwright? Spin up subprocesses? Use multiprocessing for parallel work? None of that works in Pyodide — it's fundamentally constrained by what WebAssembly can do.
CodeRunner runs actual CPython in Apple containers. Real filesystem access. Real network. Real parallelism. The tradeoff is you need a macOS machine to run it on.
When Pyodide Makes Sense
To be fair, Pyodide has its place:
- Browser-only apps where you can't run a server
- Zero-infrastructure demos
- Simple scripts with pure Python dependencies
But for real-world Python workloads — data science, ML, web scraping, file processing — CodeRunner is the better tool for the job.
Complete Example
import dspy
from instavm import InstaVM
# <> Insert Instavm Adapter code present in the Appendix of this blog post.
# Setup
lm = dspy.LM('openai/gpt-4o-mini')
dspy.configure(lm=lm)
# New users get free credits to try it out
vm = InstaVM(api_key="your_key", timeout=50)
# Or use locally deployed coderunner
vm = InstaVM(base_url="http://coderunner.local:8222", timeout=50)
pot = dspy.ProgramOfThought("question -> answer", interpreter=InstaVMInterpreter(vm))
# Examples
questions = [
"What is the sum of squares from 1 to 10?",
"Calculate factorial of 12",
"If a car travels at 65 mph for 3.5 hours, how far does it go?",
]
for question in questions:
result = pot(question=question)
print(f"Q: {question}")
print(f"A: {result.answer}\n")Resources
- DSPy ProgramOfThought Tutorial: dspy.ai/tutorials/program_of_thought
- DSPy: dspy.ai
- InstaVM: instavm.io
- CodeRunner (local): github.com/instavm/coderunner
Summary
DSPy provides the flexibility to use any other python interpreter for DSPy's ProgramOfThought and in this blog we covered how InstaVM can be used with DSPy -
- Import InstaVM:
from instavm import InstaVM - Copy adapter: ~80 line
InstaVMInterpreterclass (see Appendix) - Use it:
pot = dspy.ProgramOfThought("question -> answer", interpreter=InstaVMInterpreter(vm))
That's it! You now have code driven reasoning with accurate, reproducible results. We think of it as grounding the final result with real answers using code execution.
Appendix: Complete Adapter Code
Click to expand: Full InstaVMInterpreter implementation (~80 lines)
import json
from typing import Any
from instavm import InstaVM
class InstaVMInterpreter:
"""
Lightweight adapter that makes InstaVM compatible with DSPy's interpreter interface.
This ~80 line class is all you need to use InstaVM with DSPy's ProgramOfThought.
Just copy it into your code - no complex imports required!
"""
def __init__(self, vm: InstaVM):
"""
Initialize the adapter with an InstaVM instance.
Args:
vm: An initialized InstaVM instance
"""
self.vm = vm
def _inject_variables(self, code: str, variables: dict[str, Any]) -> str:
"""Inject variables into code as Python assignments."""
injected_lines = []
for key, value in variables.items():
if not key.isidentifier():
raise ValueError(f"Invalid variable name: '{key}'")
# Serialize value to Python code
if isinstance(value, str):
python_value = repr(value)
elif isinstance(value, (int, float, bool)) or value is None:
python_value = str(value) if value is not None else "None"
elif isinstance(value, (list, dict)):
python_value = json.dumps(value)
else:
raise ValueError(f"Unsupported value type: {type(value).__name__}")
injected_lines.append(f"{key} = {python_value}")
if injected_lines:
return "\n".join(injected_lines) + "\n" + code
return code
def execute(self, code: str, variables: dict[str, Any] | None = None) -> Any:
"""
Execute Python code using InstaVM.
Args:
code: Python code to execute
variables: Optional dict of variables to inject into the code
Returns:
The result from InstaVM execution
"""
# Prepend final_answer function definition (required by DSPy ProgramOfThought)
# The LLM will call this function with the result
final_answer_def = """
import json as _json
def final_answer(value):
print("__FINAL_ANSWER_START__")
print(_json.dumps(value))
print("__FINAL_ANSWER_END__")
return value
"""
code = final_answer_def + code
# Inject variables if provided
if variables:
code = self._inject_variables(code, variables)
# Execute on InstaVM
result = self.vm.execute(code)
# Extract result from stdout markers
stdout = result.get('stdout', '')
if '__FINAL_ANSWER_START__' in stdout and '__FINAL_ANSWER_END__' in stdout:
start_marker = '__FINAL_ANSWER_START__\n'
end_marker = '\n__FINAL_ANSWER_END__'
start_idx = stdout.find(start_marker) + len(start_marker)
end_idx = stdout.find(end_marker)
if start_idx > len(start_marker) - 1 and end_idx > start_idx:
json_str = stdout[start_idx:end_idx].strip()
try:
parsed_result = json.loads(json_str)
return parsed_result
except json.JSONDecodeError:
pass
return result
def __call__(self, code: str, variables: dict[str, Any] | None = None) -> Any:
"""Allow calling the adapter directly."""
return self.execute(code, variables)
def shutdown(self) -> None:
"""Cleanup method (no-op for InstaVM as it's API-based)."""
pass
def __enter__(self):
"""Context manager entry."""
return self
def __exit__(self, exc_type, exc_val, exc_tb):
"""Context manager exit."""
self.shutdown()