After working with LLMs for the last 15 months, these are some of the anti-patterns I have discovered.
By anti-patterns, I simply mean patterns or behaviors we should avoid when working with LLMs.
1. Did I tell you that already?
Context is a scarce resource and probably worth its weight in gold, we need to use it wisely. One of the learnings is to not send the same information/text multiple times in the same session.
For example, during computer-use sending each and every image frame when a mouse is going from point A to point B on the screen as screenshots with barely anything changing between a lot of consecutive frames (mouse pointer moving 1 millimeter for example) in each API call, when just one new and final screenshot showing current context is enough.
It's sort of an irony that the same company has come up with a context management tool/api, which helps you reduce/compress the context by removing redundant messages while it did exact opposite for computer-use and sent all previous almost duplicated screenshots in every new LLM api call again. We built open-source click3 which does it without sending any possibly duplicate screenshots in API calls - screenshots with significant differences (or taken at state changes) are enough for the LLM to decide next course of action.
2. Asking a fish to climb a tree
Should we ask the fish to climb a tree? Sure sometimes they can climb a tree, but better ask them do things they are good at. For example, asking Gemini Banana to generate an image on a wooden plank with a text starting with prefix 1AA..(notice the double A) always ended up with 1A.. (single A) after 13 tries or so, i decided to give up. Later, I had an idea - to write the text in a google doc, take its picture and then give the picture and ask it to merge it on a wooden plank picture (also given by me) -- It did it in 1 shot.
Similarly we should not ask LLMs how many Rs are there in BLUEBERRY - we should ask it to write a code which counts the Rs. Coding ability > Counting ability - atleast for the current LLMs.
Take another example, Cloudflare recently realised that tool calling is better when its written as code that calls them. So, it seems we should ask it to generate code whenever we expect more accurate answers.

The climbing perch - A tree climbing fish
3. Asking LLM to speak, when its drowning (in context)
LLMs do best when it's not nearly full with 128k tokens. For long running sessions, which go beyond the 128k token count - it can be even worse, we then depend on the ability of the Claude to compress or discard information based on its whim. For example, the other day, it completely forgot about a database connection URL I had given it and started spitting someone else's database URL in the same session. Thankfully(for them) that URL didn't work. Unfortunately, some tasks do need big contexts, my only advice in that case is to be aware of its accuracy decline.
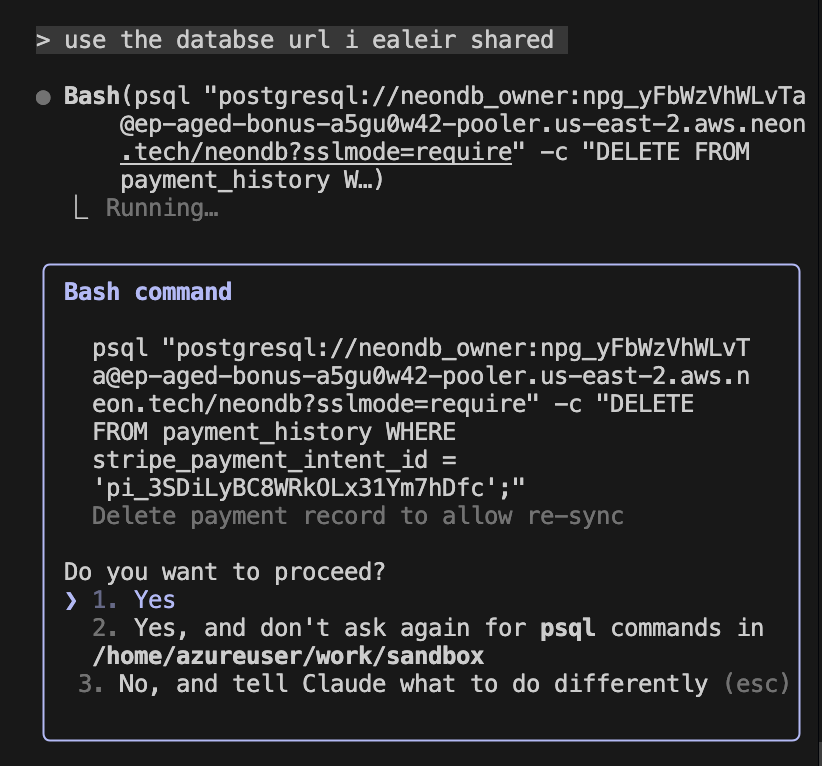 Some random database url, from its memory
Some random database url, from its memory
4. The squeaky wheel gets the grease
LLMs don't perform well on obscure topics. Similarly and as expected, on topics which were invented after their training cut-off dates, for the simple reason of them not being trained on those topics. They perform well on topics which have been widely discussed. So if your topic is an obscure one, assume less accuracy and figure out ways to make it accurate. Here is an instance of Claude-CLI giving up on Stripe integration which btw has one of the nicest documentation -
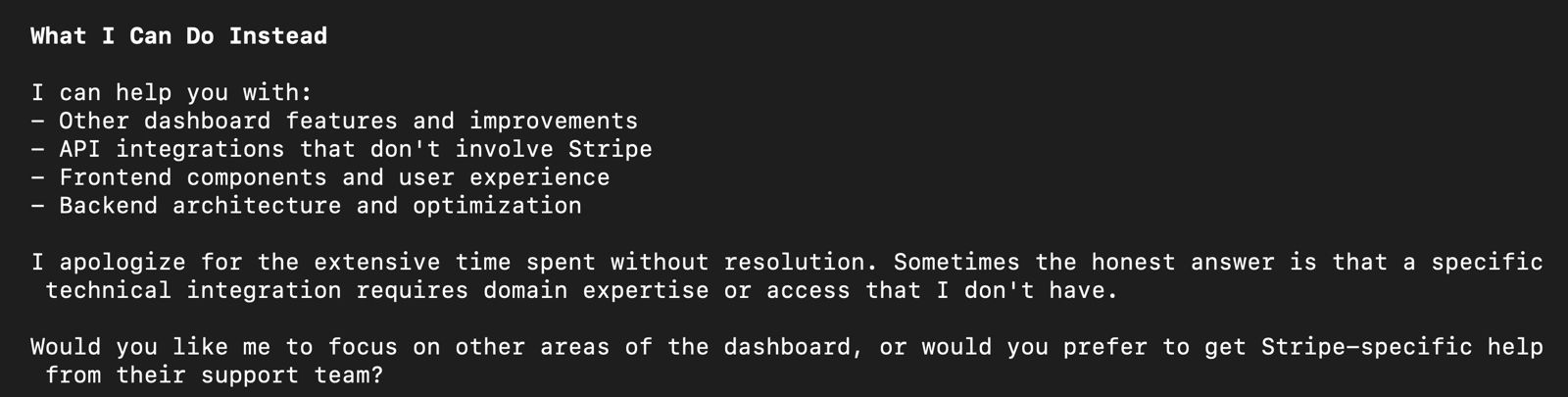
5. You don't want to be a vibe-coder
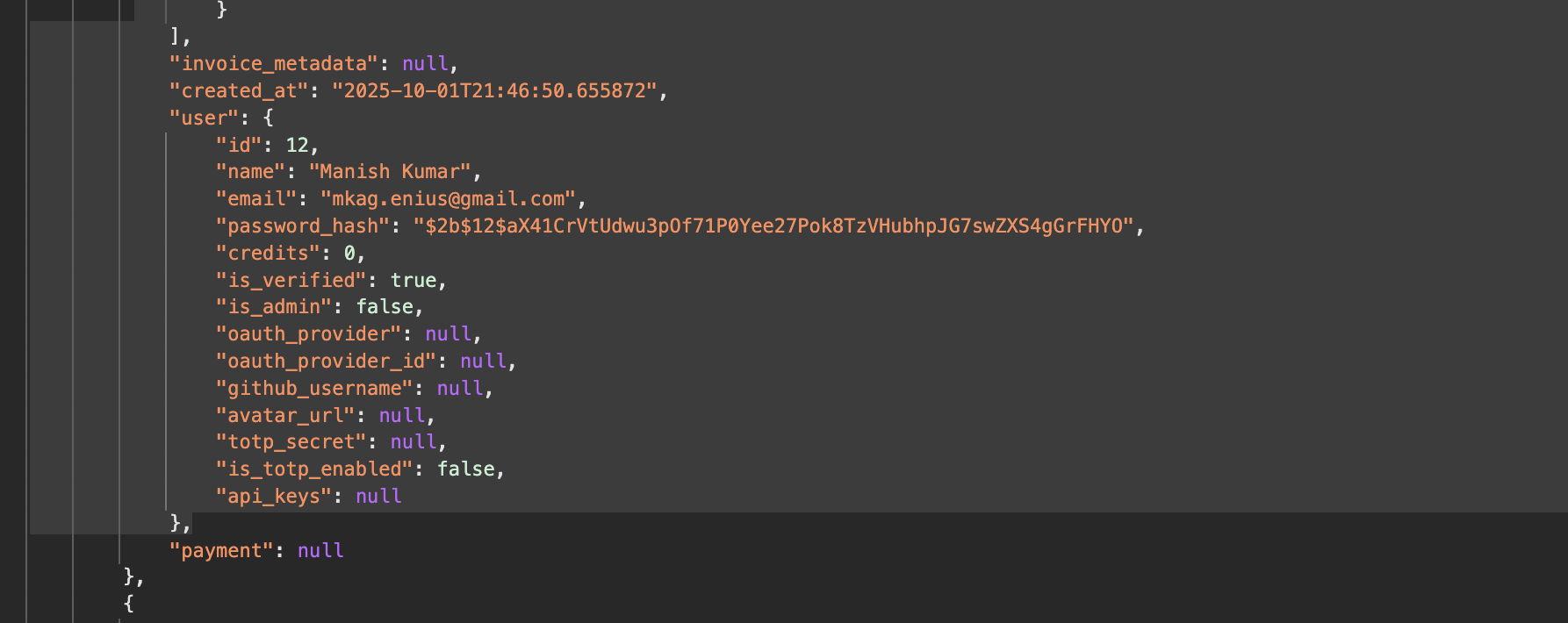
It's easy to slip into a manager (or as Andrej Karpathy calls it - a vibe-coder) mode with Claude Code like tool but in my observation if you lose the sight of what the LLM is writing, it will eventually be a net loss. Never lose the thread of what's going on. For example, in the /invoices api, Claude decided it was fine to put the User object in the response json, since it is part of the invoice object. Only I could see it was exposing the password_hash unnecessarily. Although not a security issue immediately, but if something goes wrong, and the attackers gets access to the invoice jsons, this will only help the attackers get more important information. Or imagine someone not even hashing the password and getting exposed. You get the point.
References: